Full text search Draw.io (diagrams.net) diagram in Nextcloud

Full text search in Nextcloud is a great feature. It includes LibreOffice files. However, I found that Draw.io files are not included. This is just some notes on the idea to include .drawio files to Nextcloud full text search. It should be developed as a plugin later.
.drawio file type is an XML
Here’s a sample .drawio file opened in text editor:
<mxfile host="embed.diagrams.net" modified="2022-02-17T15:39:04.371Z" agent="5.0 (Windows)" etag="cR5UYiRQA5ij_U9vdlQz" version="16.5.6" type="embed"><diagram id="AuVbhCTzAwpeFgywoMie" name="Page-1">vLzHsuPKEiT4NW9PaGAJrSWhd9CaJDTAr59Mnnun+1lPm82mu4xWRYJgIkWEh3tEZv0H46dLXrJPa77LavwP+iiv/2DCf1CUIWnwN7xw/13ACfLvQrN05d8l5H9ceHbf6p+Lj3+u7l1Zrf914/Z+j1v3+e+Lxfv1qortv65ly/I+//u2+j3+91M/WVP9LxeeRTb+r1ejrtzaf64iJPM/vlCqrmn/eTSNUn9fTNm/N/8zkrXNyvf5P13CxP9g/PJ+b3/vpouvRjh3/87L3++k/823/2/Hluq1/f/5Afr3gyMb93/G9k+/tvvfwYIufuDbbvrNCndUy9aBuTCyvBqd99pt3fsFvs/f2/aewA0j/ILLiqFZ3vur5N/jewHfl1Wd7eP2P7XAjl0Df7m9P+Bqtn7+1qrurgp0j/s9kP336uPfK7CpbMv+g7F/H1Hp82r+g/JdyNne+dDl5s2CP9YzaMWgAe8o+FHjeDYB/3Lgfk566eBtw4qj6IYeHu9XyZVt4HnFf1CuVIq+T5rHc5jUUhw+Qql2YqN2uoPz4nsOOrZ5P4f51YqtpvNBg3mIXoJWbQ/8RX1f9E1gDHNUR32UmI99HbVfsX7DiM+DskH7BSNXdpp1niVyLHhJnMuxv5cbsK4IX4HEigJLsL0sntqHbiMPB4NqVPh666zKw5fONzz7e/Uq60bK4P1v2wLPaRqVU3OOW4Pzfop/1/4/789Xkdlzi1cWnBZEpj6uQORUeDsYnqqxjet9qwBYFVc9zY5QwBs+MBqXe9yiqz3wtWuHLzeEoiPkJSp7bDOwuHqxSzjcuvwtIiyH5ohKuna1gzEY7CBLrq6JxXP8PF6NfaF3fFokKQUyln/pAdzKI7+5qsXit975UDpKF+cfzD8JF2PkQAHPp2/ZVYeQfn7UQfk8iIKx6IYwPd7V2l4UAORwhvgOyHQo7W+y+ZzsZsnOs27MtsOt6flwVxblTewRLxcwfGgpZT2ujyqW1+39DS52AleZManQ3Jni7wel8krz7o0Fs6yw0enfRLAJUW5OHwYgAQdX+7NJmF7DFZNVjiU3V5vlJZTQF8k...
(...)
</diagram></mxfile>Drawio format “mxfile” is an XML file with deflated content of the diagram.
Nextcloud files full text search app
App source is available at:
https://github.com/nextcloud/files_fulltextsearch.git
File types are handled in “FilesService.php” located in:
NEXTCLOUD_ROOT/apps/files_fulltextsearch/lib/Service/FilesService.phpJust for a test, add applicaiton/xml to be recognized as TEXT file, in parseMimeTypeText() function like below at line 861.
847 /**
848 * @param string $mimeType
849 * @param string $extension
850 * @param string $parsed
851 *
852 * @throws KnownFileMimeTypeException
853 */
854 private function parseMimeTypeText(string $mimeType, string $extension, string &$parsed) {
855
856 if (substr($mimeType, 0, 5) === 'text/') {
857 $parsed = self::MIMETYPE_TEXT;
858 throw new KnownFileMimeTypeException();
859 }
860
861 // 20220219 Parse XML files as TEXT files
862 if (substr($mimeType, 0, 15) === 'application/xml') {
863 $parsed = self::MIMETYPE_TEXT;
864 throw new KnownFileMimeTypeException();
865 }
866
867 $textMimes = [
868 'application/epub+zip'
869 ];
870
871 foreach ($textMimes as $mime) {
872 if (strpos($mimeType, $mime) === 0) {
873 $parsed = self::MIMETYPE_TEXT;
874 throw new KnownFileMimeTypeException();
875 }
876 }
877
878 $this->parseMimeTypeTextByExtension($mimeType, $extension, $parsed);
879 }
880
Restart nextcloud-fulltext-elasticsearch-worker:
sudo systemctl restart nextcloud-fulltext-elasticsearch-workerPut an xml file in Nextcloud (sample taken from simple.xml ):

Try search in Nextcloud.
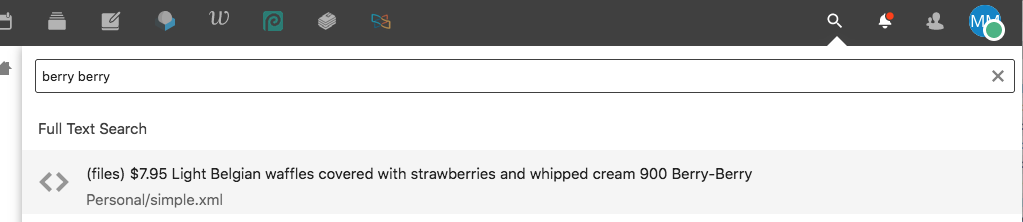
Exact match should be indicated by bold letters.

So far, so good.
.drawio file is an XML file, but deflated.
Here is a very simple Drawio diagram:
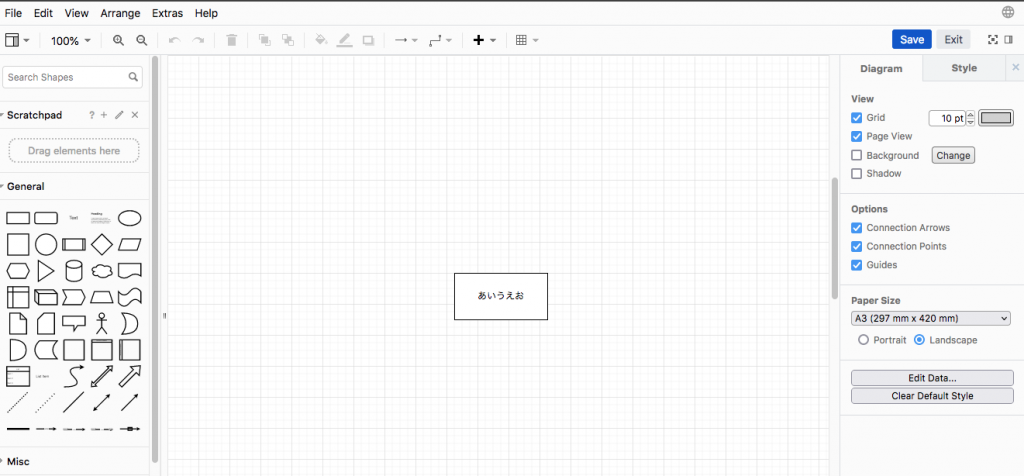
and the .drawio file is like this:
<mxfile host="embed.diagrams.net" modified="2022-02-20T03:14:32.065Z" agent="5.0 (Macintosh)" etag="mZv-Ht9U0wXalCt4k_3Y" version="16.6.1" type="embed"><diagram id="bwsSY7Qtgjerim4sss-x" name="Page-1">jZLBboMwDIafJncgK+uuY1132YlDzxnxSKRAUGoK9OkXFqeA0KRdkP39NrH/hPGiGc9OdOrTSjAsS+TI+BvLsiM/+O8MpgDyJAmgdloGlC6g1HcgGMt6LeG6KURrDepuCyvbtlDhhgnn7LAt+7Zme2onatiBshJmTy9aoiKaH54W4QN0reLRaf4SlEbEalrlqoS0wwrxE+OFsxZD1IwFmNm8aEzoe/9DfUzmoMX/NGSh4SZMT8uJr0oCDYdTXNnZvpUwNyWMvw5KI5SdqGZ18HfsmcLG+Cz14X4ImusGDmFcIRrqDLYBdJMvIZU/k0H0RLIj5cPK8GiiWnmdExN0x/Xj14sLPiAjYroY/qutni0//QA=</diagram></mxfile>So in draw.io file with .drawio extension, the diagram XML is in the “diagram” element of the XML, base64 encoded and deflated.
* Draw.io diagram has XML export function without compression. Then you can save a full XML file directly from diagrams.net.
Instead of parsing XML file, we need to specifically read and parse “.drawio” file.
Like with XML file, we make Nextcloud app to treat “.drawio” extension as TEXT file and parse later properly, by adding the latter part below code to the same FilesService.php:
(...)
// 20220219 Parse XML files as TEXT files
if (substr($mimeType, 0, 15) === 'application/xml') {
$parsed = self::MIMETYPE_TEXT;
throw new KnownFileMimeTypeException();
}
// 20220219 Parse .drawio file
if ($extension === 'drawio') {
$parsed = self::MIMETYPE_TEXT;
throw new KnownFileMimeTypeException();
}
(...)Parsing .drawio diagram XML
Diagram.net has a conversion tool at:
https://jgraph.github.io/drawio-tools/tools/convert.html
From the JavaScript code of the tool we can see what we need to convert the element to XML:
- Base64 decode
- Inflate
- URL decode
So to do the indexing in ElasticSearch, follow the 3 steps to convert the “diagram” element and pass it to ElasticSearch, instead of the original content of .drawio file.
The same file in:
NEXTCLOUD_ROOT/apps/files_fulltextsearch/lib/Service/FilesService.phpChange extractContentFromFileText function accordingly:
- Extract diagram element
- Do the 3 steps above
- Remove image tag from the diagram as the are base64 encoded binary which is meaningless for indexing
- Pass the converted data to ElasticSearch when the file extension is “.drawio”
So it will be like this:
/**
* @param FilesDocument $document
* @param File $file
*/
private function extractContentFromFileText(FilesDocument $document, File $file) {
if ($this->parseMimeType($document->getMimeType(), $file->getExtension())
!== self::MIMETYPE_TEXT) {
return;
}
if (!$this->isSourceIndexable($document)) {
return;
}
// 20220219 Inflate drawio file
$content = $file->getContent();
if ( $file->getExtension() === 'drawio') {
try {
$xml = simplexml_load_string($content);
$deflated_content = (string)$xml->diagram;
$base64decoded = base64_decode($deflated_content, true);
$urlencoded_content = gzinflate($base64decoded);
$content = urldecode($urlencoded_content);
// Remove image tag, as they can be huge
$content = preg_replace('/style=\"shape=image[^"]*\"/', '//', $content);
} catch (\Throwable $t) {
// Error handling here
}
}
try {
$document->setContent(
// 20220219 Pass content of file, or inflated drawio graph xml
base64_encode($content), IIndexDocument::ENCODED_BASE64
// base64_encode($file->getContent()), IIndexDocument::ENCODED_BASE64
);
} catch (NotPermittedException | LockedException $e) {
}
}Result
Now the Draw.io (diagrams.net) diagram can be searched in full text search:

Remove XML tags from search result
Better search result may be without XML tags.
Add a function to strip XML tags:
/**
* @param SimpleXMLElement $element
*/
private function readXmlValue(\SimpleXMLElement $element) {
$str = '';
if( $element['value'] != null && trim(strval($element['value'])) !== '')
$str = $str . " " . trim(strval($element['value']));
if( $element != null && trim(strval($element)) !== '')
$str = $str . " " . trim(strval($element));
try {
foreach ($element->children() as $child) {
$str = $str . " " . $this->readXmlValue($child);
}
} finally {
}
// Strip HTML tags
$str_without_tags = preg_replace('/<[^>]*>/', ' ', $str);
return $str_without_tags;
}
And call this function before passing the content of XML to ElasticSearch. So the function extractContentFromFileText will be:
/**
* @param FilesDocument $document
* @param File $file
*/
private function extractContentFromFileText(FilesDocument $document, File $file) {
if ($this->parseMimeType($document->getMimeType(), $file->getExtension())
!== self::MIMETYPE_TEXT) {
return;
}
if (!$this->isSourceIndexable($document)) {
return;
}
// 20220219 Inflate drawio file
$content = $file->getContent();
if ( $file->getExtension() === 'drawio') {
try {
$xml = simplexml_load_string($content);
// Initialize $content
$content = '';
// Iterate all the 'diagram' tags
foreach ($xml->diagram as $child) {
$deflated_content = (string)$child;
$base64decoded = base64_decode($deflated_content);
$urlencoded_content = gzinflate($base64decoded);
$urldecoded_content = urldecode($urlencoded_content);
// Remove image tag
$diagram_str = preg_replace('/style=\"shape=image[^"]*\"/', '', $urldecoded_content);
$content = $diagram_str;
// Construct XML document of diagram
$diagram_xml = simplexml_load_string($diagram_str);
$content = $content . ' ' . $this->readXmlValue($diagram_xml);
}
} catch (\Throwable $t) {
// Exception handling
}
}
try {
$document->setContent(
// 20220219 Pass content of file, or inflated drawio graph xml
base64_encode($content), IIndexDocument::ENCODED_BASE64
// base64_encode($file->getContent()), IIndexDocument::ENCODED_BASE64
);
} catch (NotPermittedException | LockedException $e) {
}
}
This way, the retrieved diagram’s XML is:
資産 Assets サービス Producst /Services 価値 Value 売上 / 利益 Sales / Profit 技術力 対話能力 製品・ソリューションの知識 経験 仕組み 製品 教育 規定 インフラ 管理部 エンジニア・派遣 プロジェクトマネジメント 品質管理 経験 仕組み 製品 教育 規定 インフラ 管理部 自社製品 他社製品/OSS製品 自社サービス
No XML nor HTML tags are included, but only words used in the .drawio file are used to index the file.
Search result looks better now: